参考链接
0. 说明
在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高可用(HA)的自动容灾配置
Hadoop 高可用
High Availablility 相当于再配置一台 NameNode单节点模式容易产生单点故障
冷备份和热备份的区别 热备份:有两个 NameNode 同时工作,其中一台机器处于 active 状态,另一台机器处于 standby 状态。 两个节点数据是即时同步的,起同步作用的进程成为 JournalNode
冷备份:相当于 SecondaryNameNode
1. NameNode & DataNode 多目录配置
0. 关闭集群
stop-all.sh
1. NameNode 多目录配置
目的:用于冗余,存储多个镜像文件副本
# 编辑 hdfs-site.xmlsudo vim /soft/hadoop/etc/hadoop/hdfs-site.xmldfs.namenode.name.dir /home/centos/hadoop/dfs/name1,/home/centos/hadoop/dfs/name2
分发配置文件
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml
重命名 name 文件夹为 name1 ( 在 /home/centos/hadoop/dfs 目录执行以下操作 )
mv name name1
拷贝 name1 文件夹到 name2
cp -r name1 name2
2. DataNode 多目录配置
目的:用于扩容,将所有数据文件存放在不同的磁盘设备上,如 SSD 等等
# 编辑 hdfs-site.xmlsudo vim /soft/hadoop/etc/hadoop/hdfs-site.xml
dfs.datanode.data.dir /home/centos/hadoop/dfs/data1,/home/centos/hadoop/dfs/data2
分发配置文件
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml
重命名 data 文件夹为 data1
xcall.sh mv /home/centos/hadoop/dfs/data /home/centos/hadoop/dfs/data1
启动 HDFS
start-dfs.sh
3. 配置高可用(冷备份)
3.0 拷贝 full 文件夹到 ha
# 复制 Hadoop 配置文件cp -r /soft/hadoop/etc/full /soft/hadoop/etc/ha# 更改软链接ln -sfT /soft/hadoop/etc/ha /soft/hadoop/etc/hadoop
3.1 修改 hdfs-site.xml
dfs.replication 3 dfs.namenode.secondary.http-address s105:50090 dfs.namenode.name.dir /home/centos/ha/dfs/name1,/home/centos/ha/dfs/name2 dfs.datanode.data.dir /home/centos/ha/dfs/data1,/home/centos/ha/dfs/data2 dfs.nameservices mycluster dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 s101:8020 dfs.namenode.rpc-address.mycluster.nn2 s105:8020 dfs.namenode.http-address.mycluster.nn1 s101:50070 dfs.namenode.http-address.mycluster.nn2 s105:50070 dfs.namenode.shared.edits.dir qjournal://s102:8485;s103:8485;s104:8485/mycluster dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods shell(/bin/true)
3.2 修改 core-site.xml
fs.defaultFS hdfs://mycluster dfs.journalnode.edits.dir /home/centos/ha/dfs/journal/node/local/data hadoop.tmp.dir /home/centos/ha
3.3 修改 slaves 文件
s102s103s104
3.4 配置 s105 的 SSH 免密登陆
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsassh-copy-id centos@s101ssh-copy-id centos@s102ssh-copy-id centos@s103ssh-copy-id centos@s104ssh-copy-id centos@s105
3.5 将 s101 的工作目录发送给 s105
删除 s102-s105 的配置文件,不要用 xcall.sh 脚本ssh s102 rm -rf /soft/hadoop/etcssh s103 rm -rf /soft/hadoop/etcssh s104 rm -rf /soft/hadoop/etcssh s105 rm -rf /soft/hadoop/etc
将 s101 配置文件分发
xsync.sh /soft/hadoop/etc
3.6 启动 JournalNode
hadoop-daemons.sh start journalnode
3.7 格式化 NameNode
hdfs namenode -format
3.8 将 s101 的 ha 目录发送给 s105
scp -r ~/ha centos@s105:~
3.9 启动 HDFS ,观察 s101 和 s105 的 NameNode 情况
start-dfs.sh
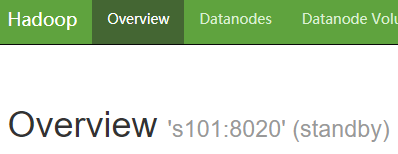
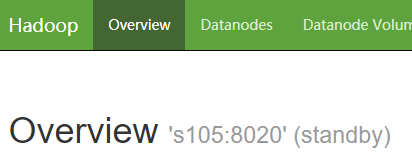
3.10 手动切换 s101 的 NameNode 为 active 状态
hdfs haadmin -transitionToActive nn1
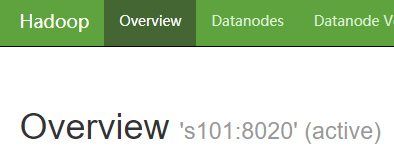
4. 配置高可用(热备份)
4.0 说明
Hadoop 高可用热备份的配置建立在冷备份的配置基础之上
4.1 关闭 Hadoop
stop-all.sh
4.2 启动 s102-s104 的 ZooKeeper
zkServer.sh start
4.3 修改 hdfs-site.xml ,添加以下内容
dfs.ha.automatic-failover.enabled true
4.4 修改 core-site.xml ,添加以下内容
ha.zookeeper.quorum s102:2181,s103:2181,s104:2181
4.5 分发配置文件
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml xsync.sh /soft/hadoop/etc/hadoop/core-site.xml
4.6 初始化 ZooKeeper
hdfs zkfc -formatZK
4.7 启动 HDFS
start-dfs.sh
4.8 查看进程
xcall.sh jps
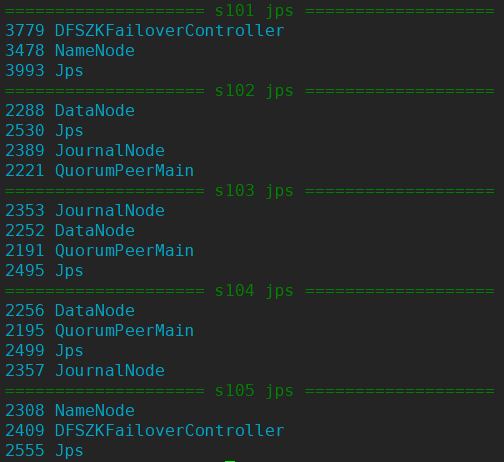
4.9 启动 Zookeeper 命令行脚本 zkCli.sh
zkCli.sh
5. 测试 Hadoop 高可用(HA)的自动容灾
5.0 说明
通过关闭 s101 的 NameNode 进程验证 Hadoop 高可用的自动容灾
5.1 通过 Web 查看 Hadoop 两个节点 s101 、s105 的状态
http://192.168.23.101:50070
http://192.168.23.105:50070


5.2 关闭 s101
已知 s101 的 NameNode 进程 id 为 3478
kill -9 3478
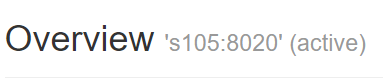
5.3 再次查看 Hadoop 两个节点 s101 、s105 的状态
通过 Web 可以看出 s105 的状态为 active ,实现了自动容灾

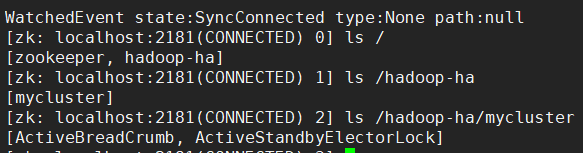
6. 查看 Hadoop 高可用文件
在 s102 启动 ZooKeeper 命令行( zkCli.sh ),再执行以下操作
其中:
- ActiveStandbyElectorLock 是临时结点,负责存储 active 状态下的节点地址
- ActiveBreadCrumb 是永久结点,负责在 ZooKeeper 会话关闭时,下一次启动状态下正确分配 active 节点,避免脑裂(brain-split),即两个 active 节点状态
[zk: localhost:2181(CONNECTED) 0] ls /[zookeeper, hadoop-ha][zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha[mycluster][zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha/mycluster[ActiveBreadCrumb, ActiveStandbyElectorLock][zk: localhost:2181(CONNECTED) 3] get /hadoop-ha/mycluster/ActiveBreadCrumb myclusternn1s101 �>(�>cZxid = 0x500000008ctime = Thu Sep 27 10:16:23 CST 2018mZxid = 0x500000016mtime = Thu Sep 27 11:13:05 CST 2018pZxid = 0x500000008cversion = 0dataVersion = 2aclVersion = 0ephemeralOwner = 0x0dataLength = 28numChildren = 0[zk: localhost:2181(CONNECTED) 4] get /hadoop-ha/mycluster/ActiveStandbyElectorLock myclusternn1s101 �>(�>cZxid = 0x500000015ctime = Thu Sep 27 11:13:05 CST 2018mZxid = 0x500000015mtime = Thu Sep 27 11:13:05 CST 2018pZxid = 0x500000015cversion = 0dataVersion = 0aclVersion = 0ephemeralOwner = 0x666618cd7c5a0005dataLength = 28numChildren = 0